Bachelor project (course 02466, Project Work — BSc Artificial Intelligence and Data, DTU, Spring 2025), with Benjamin Banks and Jonathan Tybirk.
The problem
A LiDAR scanner sees an object only from the outside, and only from some angles — you get a sparse, noisy point cloud, not the full surface. We asked: from such a point cloud alone, can a network recover the centroid of the underlying mesh? The centroid is a physically meaningful quantity: it moves and rotates exactly with the object. That makes the task a natural test case for SE(3)-equivariant networks — architectures that are mathematically guaranteed to respect 3D rotation and translation symmetry, instead of having to learn it from data.
Method
We built a strictly rotation- and translation-equivariant message-passing graph neural network (EGNN) using spherical-harmonic features and Clebsch–Gordan tensor products, following the framework of Brandstetter et al. We compared it against size-matched non-equivariant baselines: a plain GNN, and the same GNN trained with random-rotation data augmentation. All models were trained on point clouds sampled from 11,590 ShapeNet objects (800 train / 200 validation / 10,590 test) via a simulated LiDAR process.
Results
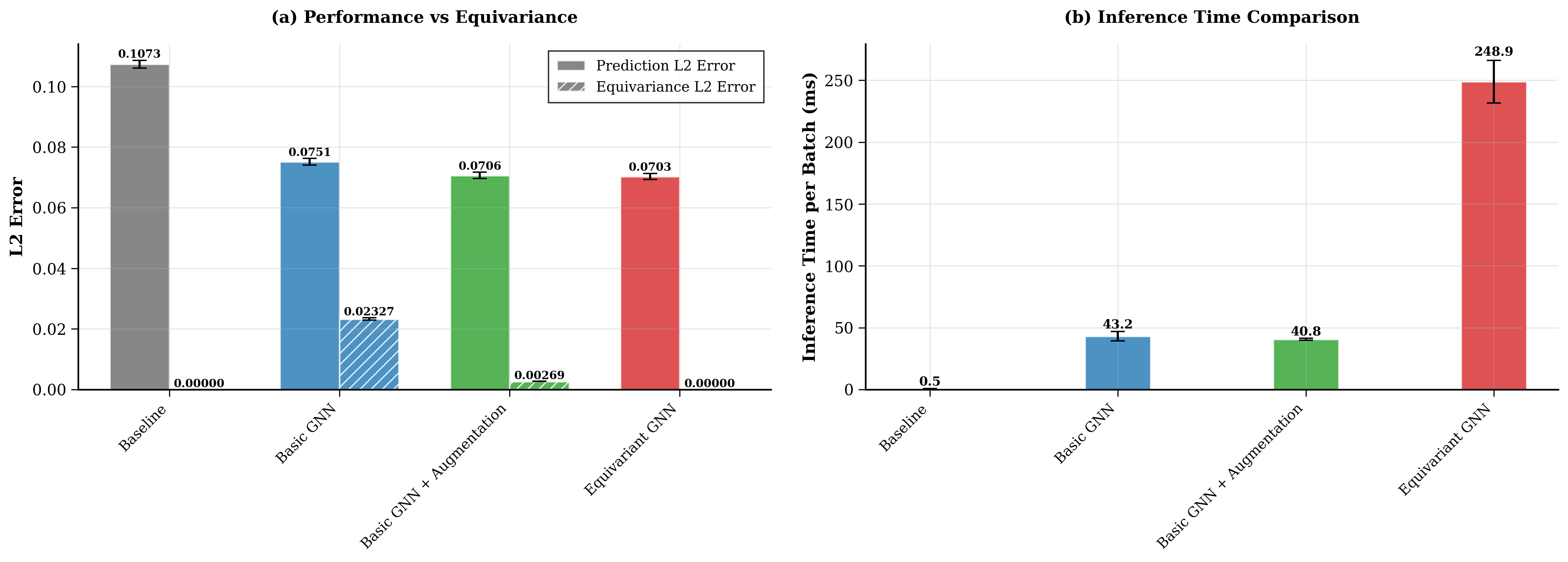
- The equivariant GNN achieved the best prediction error (0.0703 L2) while being exactly equivariant by construction (zero equivariance error).
- The augmented baseline came very close (0.0706) but retained a small residual equivariance error (0.0027) — it only approximates the symmetry.
- The price of exact symmetry: the EGNN was about 6× slower at inference (≈249 ms vs ≈41 ms per batch) due to the sparse Clebsch–Gordan tensor contractions.
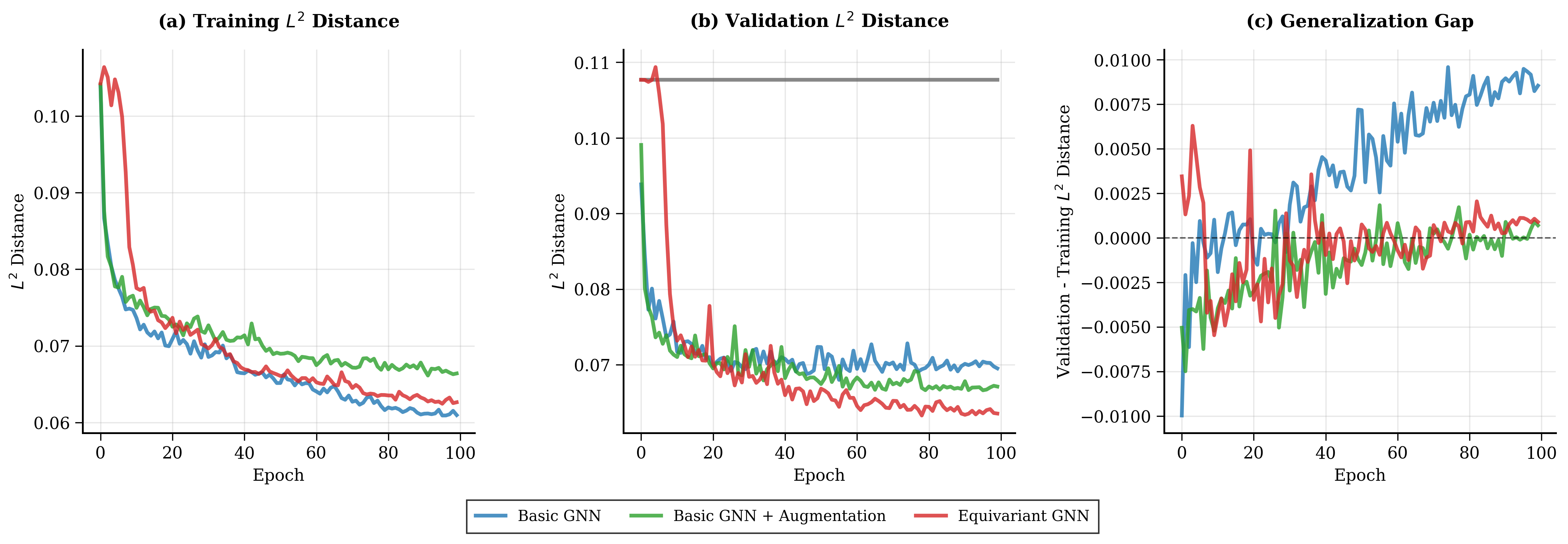
The training dynamics tell the more interesting story: the plain GNN’s generalization gap grows steadily over training, while both the equivariant model and the augmented model keep it near zero — but the equivariant model gets there by architecture rather than by data.
Takeaway: when plenty of augmented data is available, architectural equivariance is not strictly required for accuracy — but it buys exact symmetry, more stable training, and data-efficiency that matter in low-data or safety-critical settings.